Using ComicsFetcher is very simple. It could be summarized in four steps:
- Go to the comic website you like and find the image address.
Here's how you can do it with Mozilla:

Press the right mouse button on the image and
select "Copy image location" from the menu.
You should get an address such as http://www.awebcomic.com/somestrips/0023.gif.
In Internet Explorer the only way I found is to look at the HTML source, but maybe there is a better way.. well, I just don't like IE! :o)
- Look at the strip filename and find a pattern.
As you can see by the examples I've just shown there are two basic patterns:
- Numeric. Like http://www.awebcomic.com/somestrips/0023.gif
- Date. Like http://www.anothercomic.com/strips/20030106.gif
This pattern will be replaced by ComicsFetcher dynamically. This is done by using the ## string instead of the pattern when you insert the URL address in ComicsFetcher.
- Start ComicsFetcher. The main window should pop up:

Now select "Number" or "Dates" depending on the pattern type.
Set start and end number (or date) and paste the image address you just took in the "Base Img URL" field.
Using the previous (numeric type) comic as examples you should have this configuration:

Note that the Pattern field has four zeros, because the strip URL used a number having four digits.
And here is the other (date type) comic configuration:

The year in the Pattern field could also be given as yy (but not in this case). As result you would get the last two digits of the year.
Remember to select the destination directory!!
- Press Start Fetching button and enjoy!
NOTE: Sometimes the image is generated by a cgi server by giving a certain parameter.
(ie. http://www.helloworld.com/index.php?do_command=show_strip&strip_id=045&auth=0110)
The output is an image, but has no name.
ComicsFetcher can understand that, but it needs to ask for a base name, as showed here:
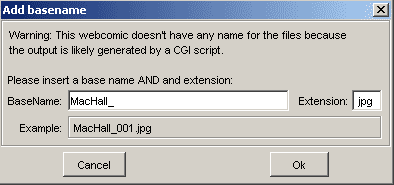
Please note that in this situation you must also give the extension. At that time ComicsFetcher can't guess the image type (maybe next release..).
|
